副函式與遞迴
副函式
之前的各個章節,我們很常使用到像是 strlen()、strcpy() 等語法,
這些都是 C/C++ 的標準函式庫所提供的函式。
而函式(Function)是程式語言中一個非常重要的概念, 它可以讓我們將一段程式碼封裝起來,並且在需要的時候重複使用。
這種封裝的方式,可以讓程式碼更易讀、更易維護, 當程式碼規模很大的時候,使用函式可以讓我們更容易地理解程式碼的結構。
除了標準函式庫提供的函式之外,我們也可以自己定義函式,
main 其實就是一個特別的函式,
它是程式的入口點,當程式執行時,系統會先執行 main 函式。
我們也能自定義自己的函式,這些自己定義的函式稱為副函式(Subroutine)或子函式(Subfunction)。
函式宣告
副函式的宣告方式如下:
return_type function_name(parameter_list) {
// 函式的程式碼
}
其中,return_type 是函式的返回值類型,function_name 是函式的名稱,parameter_list 是函式的參數列表。
如果函式沒有返回值,則 return_type 可以使用 void。
如果函式有返回值,則需要使用 return 語句來返回值。
範例
#include <iostream>
using namespace std;
int add(int a, int b)
{
return a + b;
}
int main()
{
int x = 5, y = 10;
int result = add(x, y);
cout << "The sum of " << x << " and " << y << " is: " << result << '\n';
return 0;
}
在這個範例中,我們定義了一個名為 add 的副函式,
它接受兩個整數參數 a 和 b,並返回它們的和。
在 main 函式中,我們呼叫了 add 函式,並將結果存儲在 result 變數中,
參數列表你可以想像成是函式的輸入, 我們可以設計各種不同型態的參數, 例如整數、浮點數、字串等, 這樣我們就可以在函式中使用這些參數來執行特定的操作。
範例
#include <iostream>
using namespace std;
double pow(double base, int exponent)
{
double result = 1.0;
for(int i = 0; i < exponent; ++i)
result *= base;
return result;
}
int main()
{
double base;
int exponent;
cin >> base;
cin >> exponent;
double result = pow(base, exponent);
cout << result << '\n';
return 0;
}
在這個範例中,我們定義了一個名為 pow 的副函式,
它接受一個浮點數 base 和一個整數 exponent 作為參數,
並返回 base 的 exponent 次方。
根據你的需求,你可以設計各種不同的副函式, 當然也可以不放入任何參數, 跟變數命名一樣,函數名稱也應該具有描述性, 這樣可以讓其他人更容易理解你的程式碼。
原型宣告
在副函式的使用中,如果依照剛才的宣告方式是有先後順序的,
也就是說,副函式必須在使用之前被宣告或定義,跟變數一樣,
如果我們在 main 函式中使用了某個副函式,但這個副函式還沒有被定義,
編譯器會報錯。
這時有另外一種宣告的方式,稱為原型宣告(Function Prototype)。
原型宣告可以讓我們在使用副函式之前先告訴編譯器這個函式的存在, 之後再在程式的其他地方定義它。
範例
#include <iostream>
using namespace std;
// 原型宣告
int add(int, int);
int sub(int, int);
int main()
{
int x = 5, y = 10;
int sum = add(x, y);
int difference = sub(x, y);
cout << sum << " " << difference << '\n';
return 0;
}
// 副函式定義
int sub(int a, int b)
{
return a - b;
}
int add(int a, int b)
{
return a + b;
}
在這個範例中,我們先使用原型宣告 int add(int, int); 和 int sub(int, int);,
然後在 main 函式中使用這兩個副函式。
最後在 main 函式之後定義了這兩個副函式。
這樣的寫法可以讓我們在程式中更靈活地使用副函式, 而不需要擔心函式的定義順序。
函式的重載
在 C++ 中,我們可以定義多個同名的函式,只要它們的參數列表不同, 這稱為函式的重載(Function Overloading)。 這樣可以讓我們使用相同的函式名稱來處理不同類型或數量的參數。
範例
#include <iostream>
using namespace std;
int add(int a, int b)
{
return a + b;
}
double add(double a, double b)
{
return a + b;
}
double add(double a, double b, double c)
{
return a + b + c;
}
int main()
{
int x = 5, y = 10;
double a = 2.5, b = 3.5, c = 4.5;
cout << "Integer addition: " << add(x, y) << '\n';
cout << "Double addition: " << add(a, b) << '\n';
cout << "Triple double addition: " << add(a, b, c) << '\n';
return 0;
}
在這個範例中,我們定義了三個名為 add 的函式,
它們的參數列表不同:
- 第一個
add函式接受兩個整數參數。 - 第二個
add函式接受兩個浮點數參數。 - 第三個
add函式接受三個浮點數參數。 這樣我們就可以使用相同的函式名稱來處理不同類型或數量的參數, 而不需要為每個函式都取一個不同的名稱。
函式與指標跟參考
在 C++ 中,函式的參數其實是透過複製一份變數, 然後將這份複製的變數傳遞給函式, 這樣在函式內部對參數的修改不會影響到原始變數。
假設我們現在要實現一個交換的函式, 如果我們直接使用值傳遞的方式,交換後的結果不會影響到原始變數。
範例
#include <iostream>
using namespace std;
void swap(int a, int b)
{
int temp = a;
a = b;
b = temp;
}
int main()
{
int x = 5, y = 10;
swap(x, y);
cout << "After swap: x = " << x << ", y = " << y << '\n'; // x 和 y 不會被交換
return 0;
}
在這個範例中,我們定義了一個名為 swap 的函式,
它接受兩個整數參數 a 和 b,並試圖交換它們的值。
但是,由於我們使用的是值傳遞的方式,
在 swap 函式內部對 a 和 b 的修改不會影響到 main 函式中的 x 和 y。
要讓 swap 函式能夠修改原始變數的值,我們可以使用指標或參考。
使用指標
使用指標可以讓我們直接操作變數的記憶體地址, 這樣在函式內部對參數的修改就會影響到原始變數。
範例
#include <iostream>
using namespace std;
void swap(int* a, int* b)
{
int temp = *a;
*a = *b;
*b = temp;
}
int main()
{
int x = 5, y = 10;
swap(&x, &y); // 傳遞 x 和 y 的地址
cout << "After swap: x = " << x << ", y = " << y << '\n'; // x 和 y 會被交換
return 0;
}
在這個範例中,我們定義了一個名為 swap 的函式,
它接受兩個整數指標參數 a 和 b。
在 swap 函式內部,我們使用 *a 和 *b 來訪問指標所指向的值,
並進行交換。
在 main 函式中,我們使用 &x 和 &y 傳遞 x 和 y 的地址,
這樣 swap 函式就能夠直接修改 x 和 y 的值。
使用參考 使用參考可以讓我們更簡潔地實現類似的功能, 參考是一種別名,它允許我們在函式內部直接操作原始變數,而不需要使用指標。
範例
#include <iostream>
using namespace std;
void swap(int& a, int& b)
{
int temp = a;
a = b;
b = temp;
}
int main()
{
int x = 5, y = 10;
swap(x, y); // 傳遞 x 和 y 的參考
cout << "After swap: x = " << x << ", y = " << y << '\n'; // x 和 y 會被交換
return 0;
}
在這個範例中,我們定義了一個名為 swap 的函式,
它接受兩個整數參考參數 a 和 b。
在 swap 函式內部,我們可以直接使用 a 和 b 來訪問原始變數,
並進行交換。
在 main 函式中,我們直接傳遞 x 和 y,
這樣 swap 函式就能夠直接修改 x 和 y 的值。
這樣的寫法比使用指標更簡潔,也更容易理解。
解答
解答
#include <iostream>
using namespace std;
int L(int);
int G(int);
int main()
{
int x;
cin >> x;
cout << L(G(x)) << '\n';
return 0;
}
int L(int x)
{
return 4 * x + 2;
}
int G(int x)
{
return 8 * x + 17;
}
純函數
純函數 (Pure Function)是指函式在執行時不會改變任何外部狀態, 並且對於相同的輸入總是返回相同的輸出。
舉凡像是使用 cin、cout、printf、scanf 等輸入輸出函式,
或者是透過指標或參考修改變數的函式,
都不是純函數,像是剛才的 swap 函式,就不是純函數。
這裡提到純函數的概念,是因為純函數在程式設計中有很多優點, 例如:
- 可測試性:純函數的輸出只依賴於輸入,這使得測試變得更簡單。
- 可重用性:純函數可以在不同的上下文中重複使用,而不會影響到其他部分的程式。
- 可預測性:純函數的行為是可預測的,這使得程式更容易理解和維護。
因為會閱讀本篇教學的人應該都是程式初學者,或者是要教初學者的人, 有純函數的概念在等下的遞迴章節會比較容易切入。
遞迴
函式除了可以分區功能以及重複使用之外, 我們也可以將問題用函式來切分,像是將陣列分成左右兩邊, 分別去處理問題,但是處理的邏輯是相同的, 這種情況下,我們可能會呼叫跟自己相同的函式,只是參數不同, 這種情況稱為遞迴(Recursion)。
遞迴是一種解決問題的方法,是指函式在其定義中呼叫自己, 這樣可以將一個大問題分解為多個小問題, 每次呼叫函式時,問題的規模都會縮小, 直到達到一個很小可以直接求解的情況。
我們來看一個非常經典的例子,費式數列(Fibonacci Sequence), 費式數列的定義是:
- 當
我們可以從數列中的定義發現, 的值是由 和 的值決定的, 而 和 又可以分解為更小的問題, 直到可以直接得出答案的 和 。
這個也是遞迴讓人很害怕的地方, 假設我們在數學課中想要求出 的值, 我們肯定是先算出 再去逐一推算, 而不是從 開始算起,然後拆解成兩個子問題,也就是說程式上的遞迴跟數學上的遞迴 本質上就是方向完全相反的事情,所以我們會對於程式上的遞迴的正確性抱有懷疑。
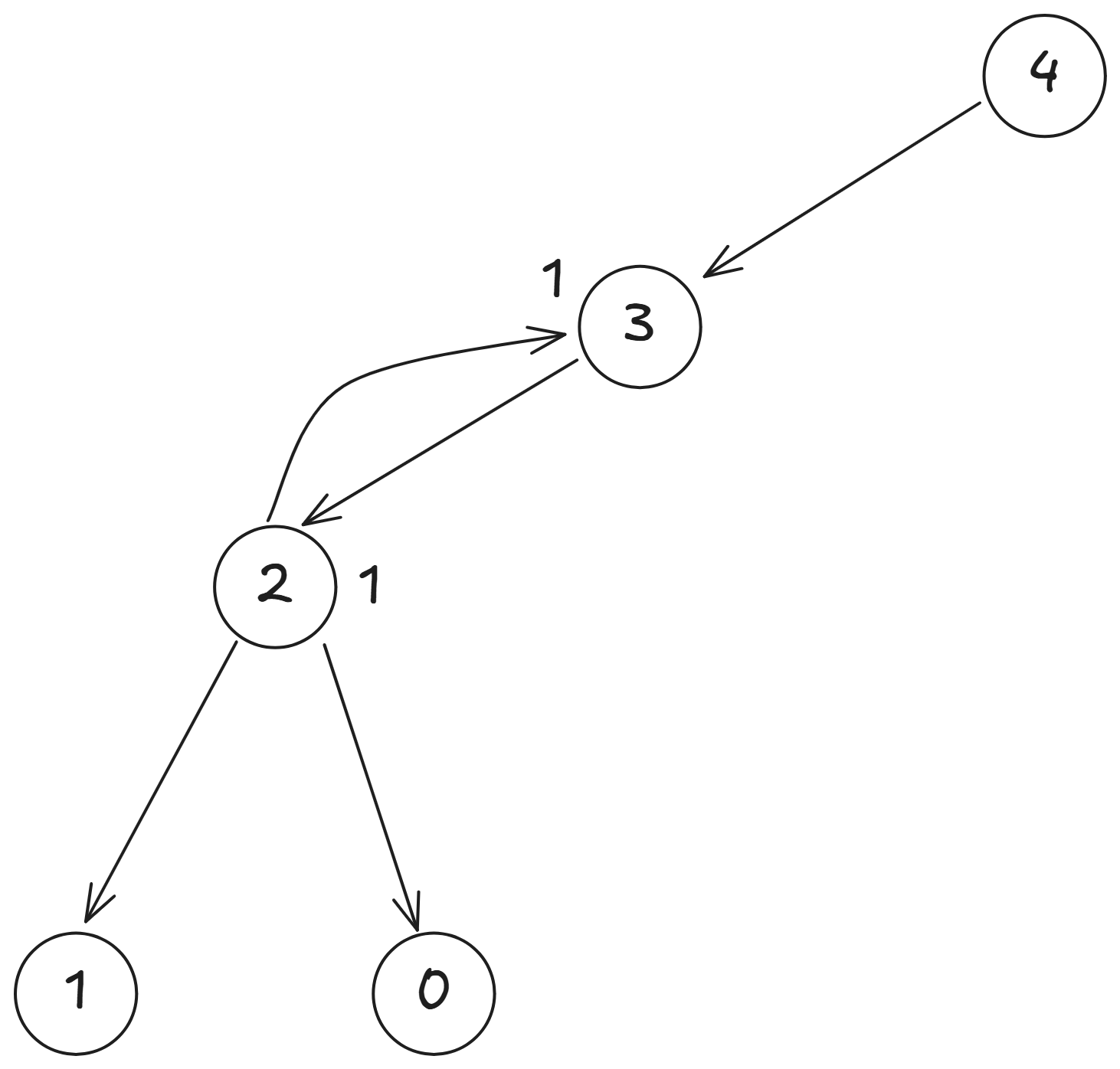
我們以 為例,來看看求解的過程:
從圖中可以看到, 的值是由 和 的值決定的,但我們還不知道 的值, 我們先從 繼續分解,
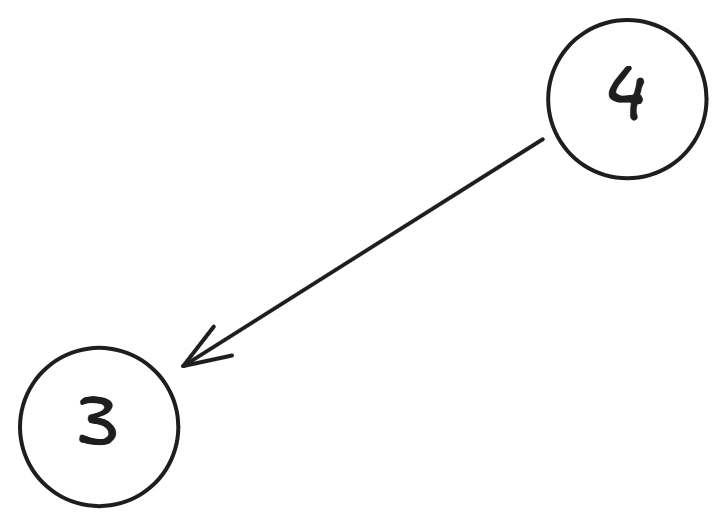
這樣我們就可以看到, 的值是由 和 的值決定的,但我們還不知道 的值,所以繼續分解 ,
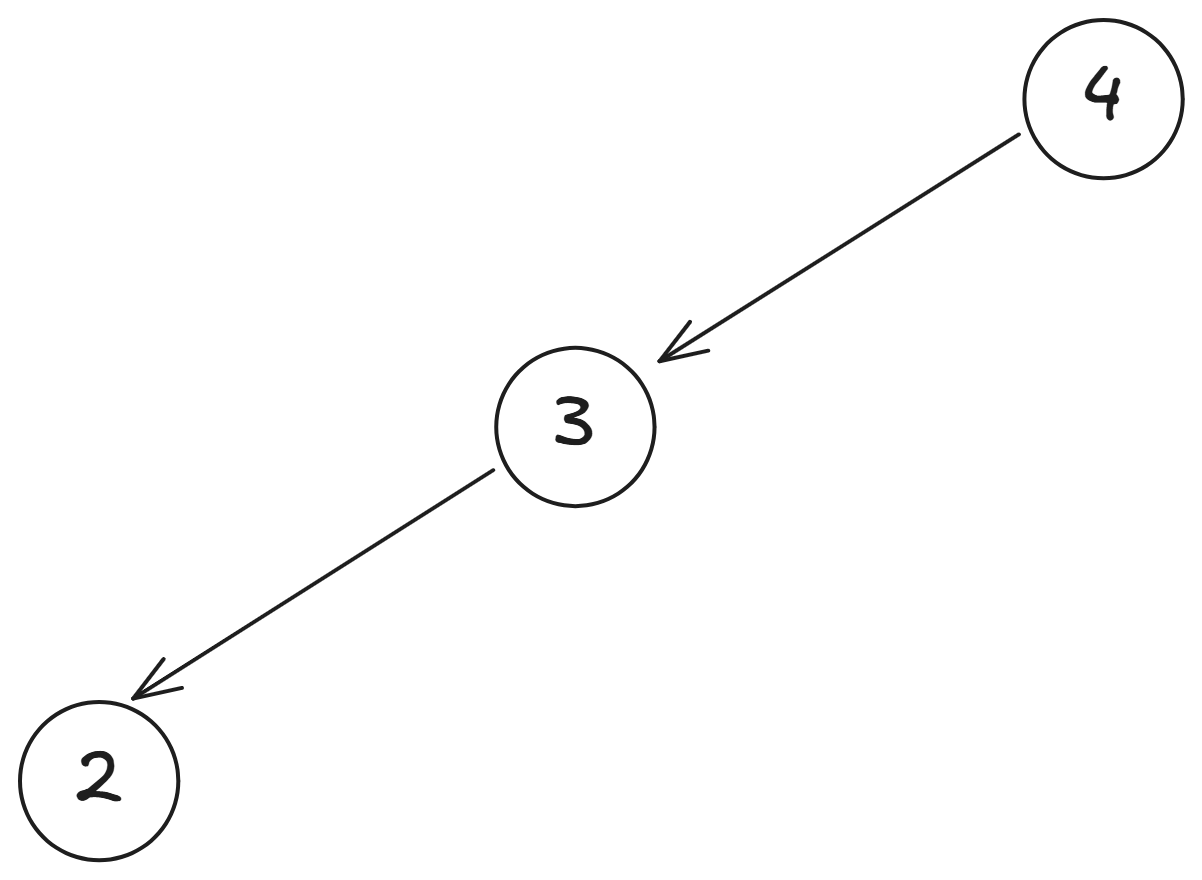
而 又可以分解為 和 ,
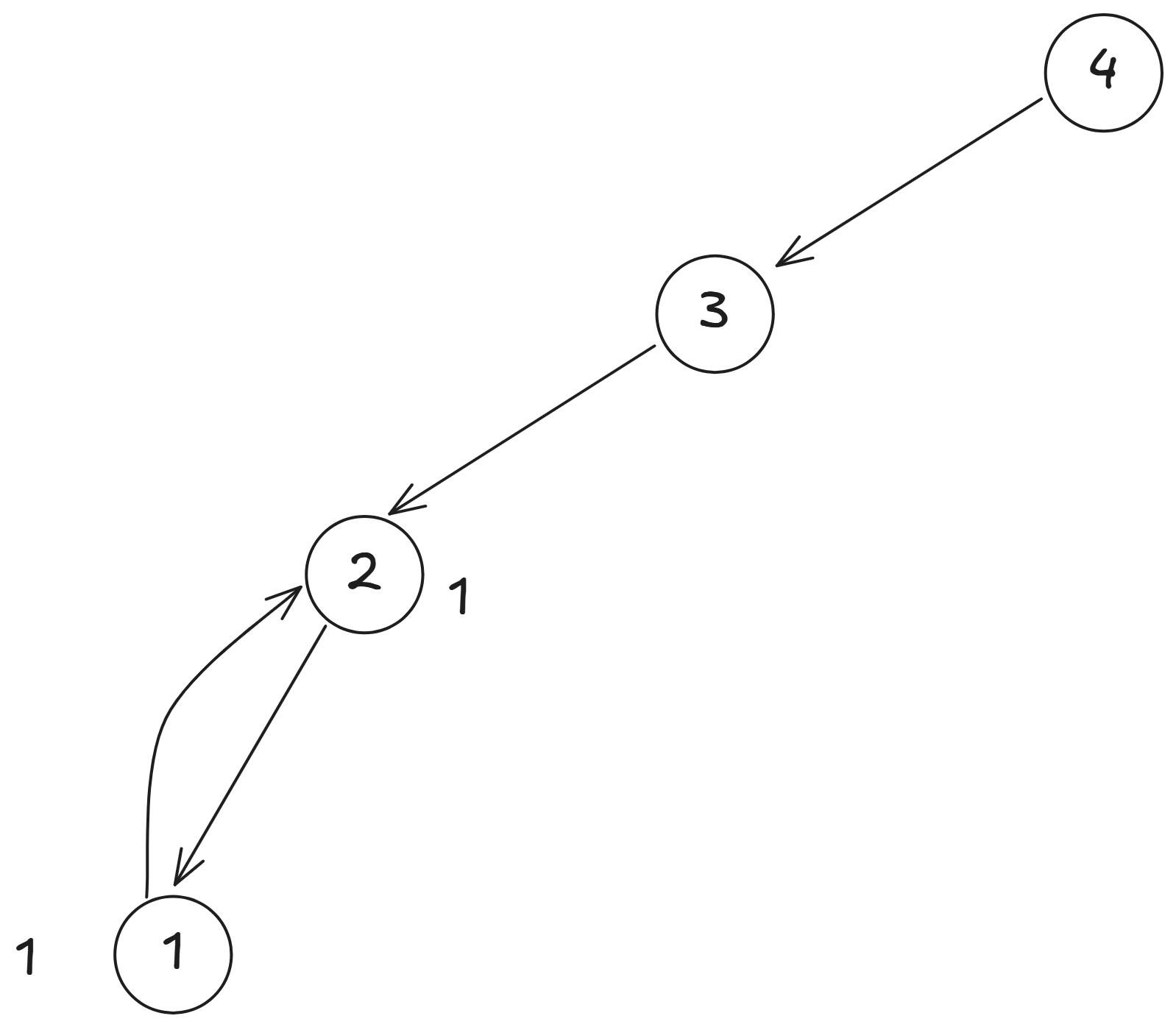
因為 是已知的,所以我們可以去看 ,
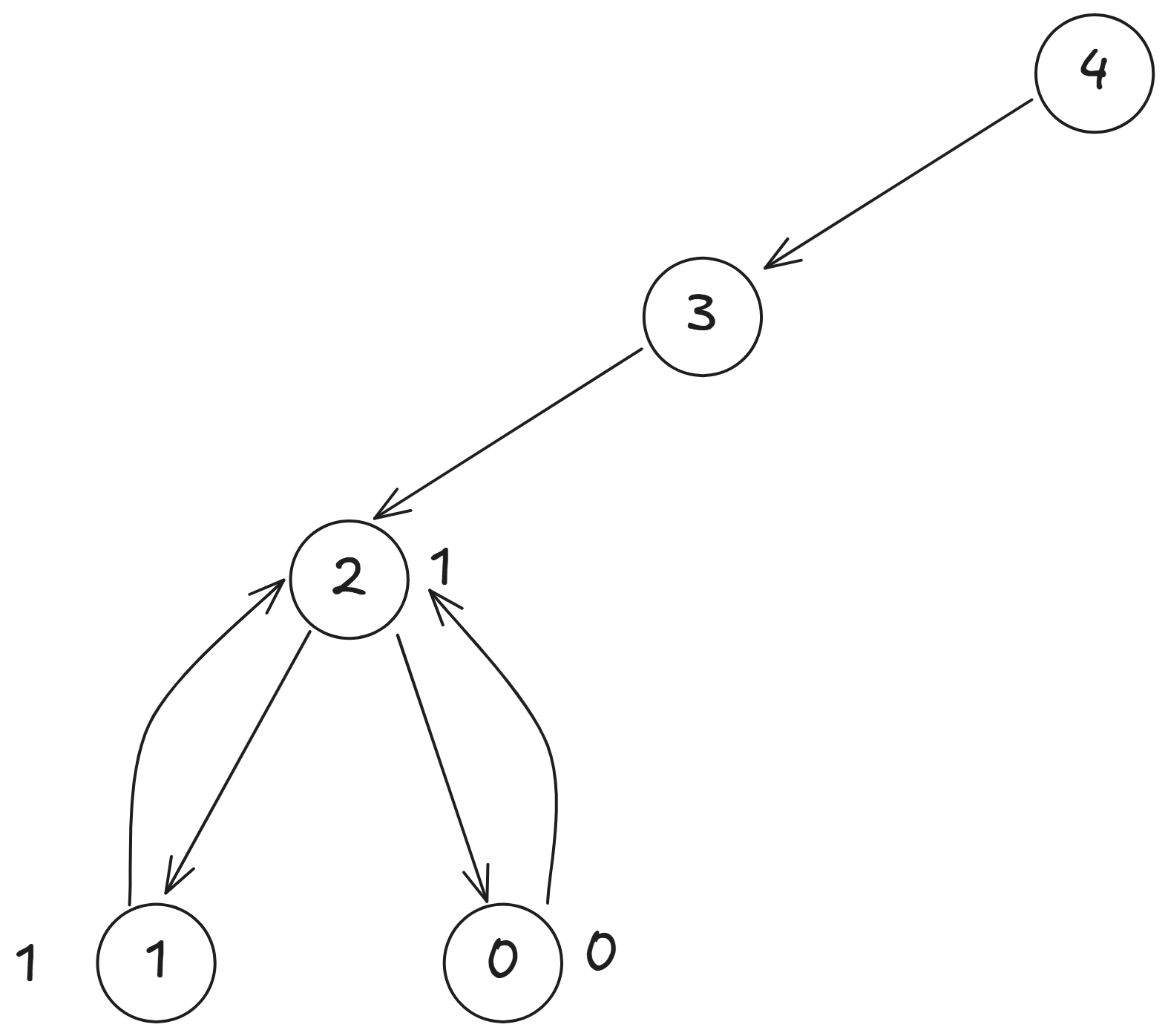
也是已知的, 所以我們可以算出 。
接著我們可以回到 , 因為 ,所以可以去看 ,
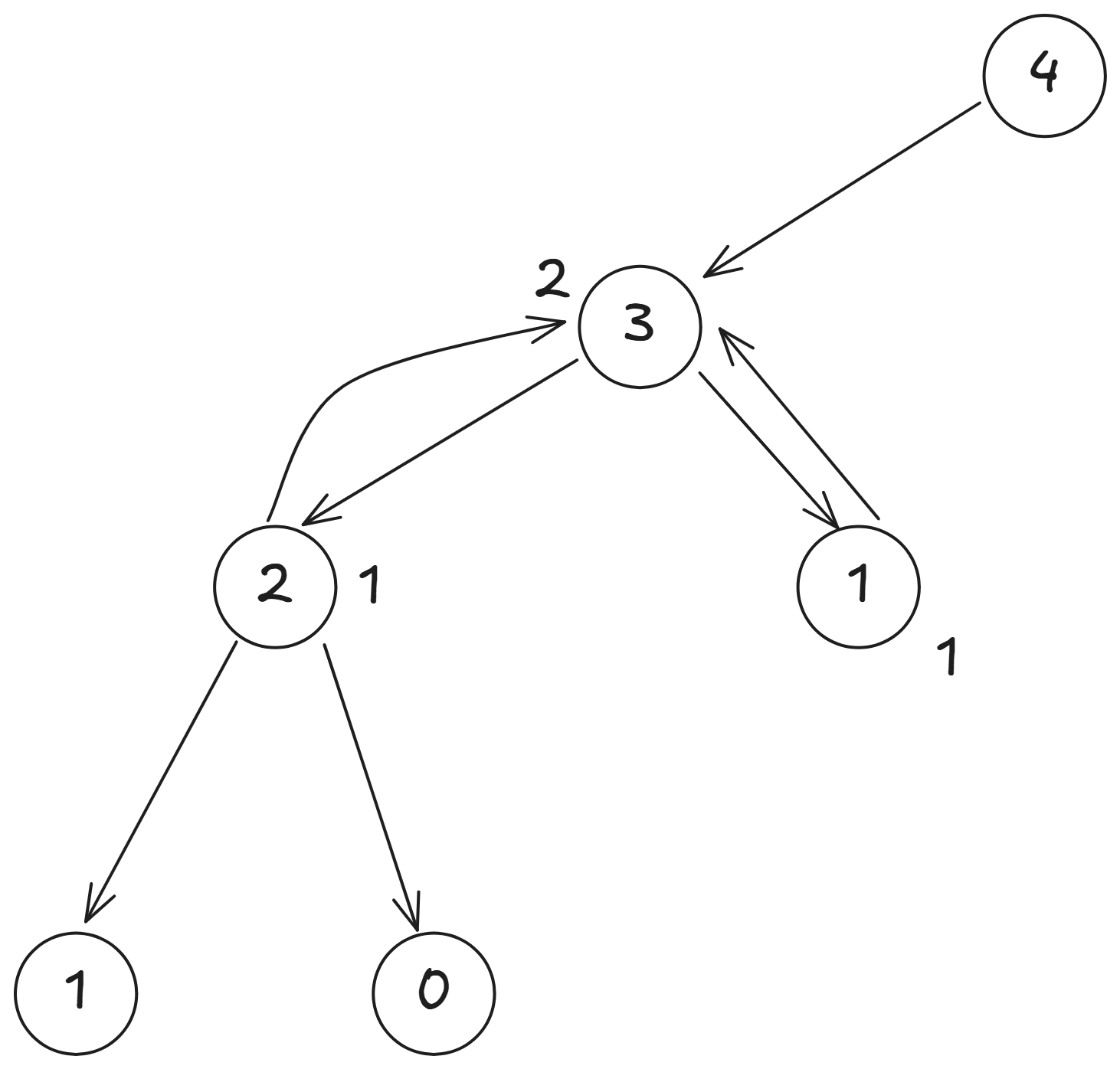
。
最後我們可以回到 , 但是右邊的 因為我們沒有儲存答案, 也不是可以直接得知的, 所以要繼續分解 ,
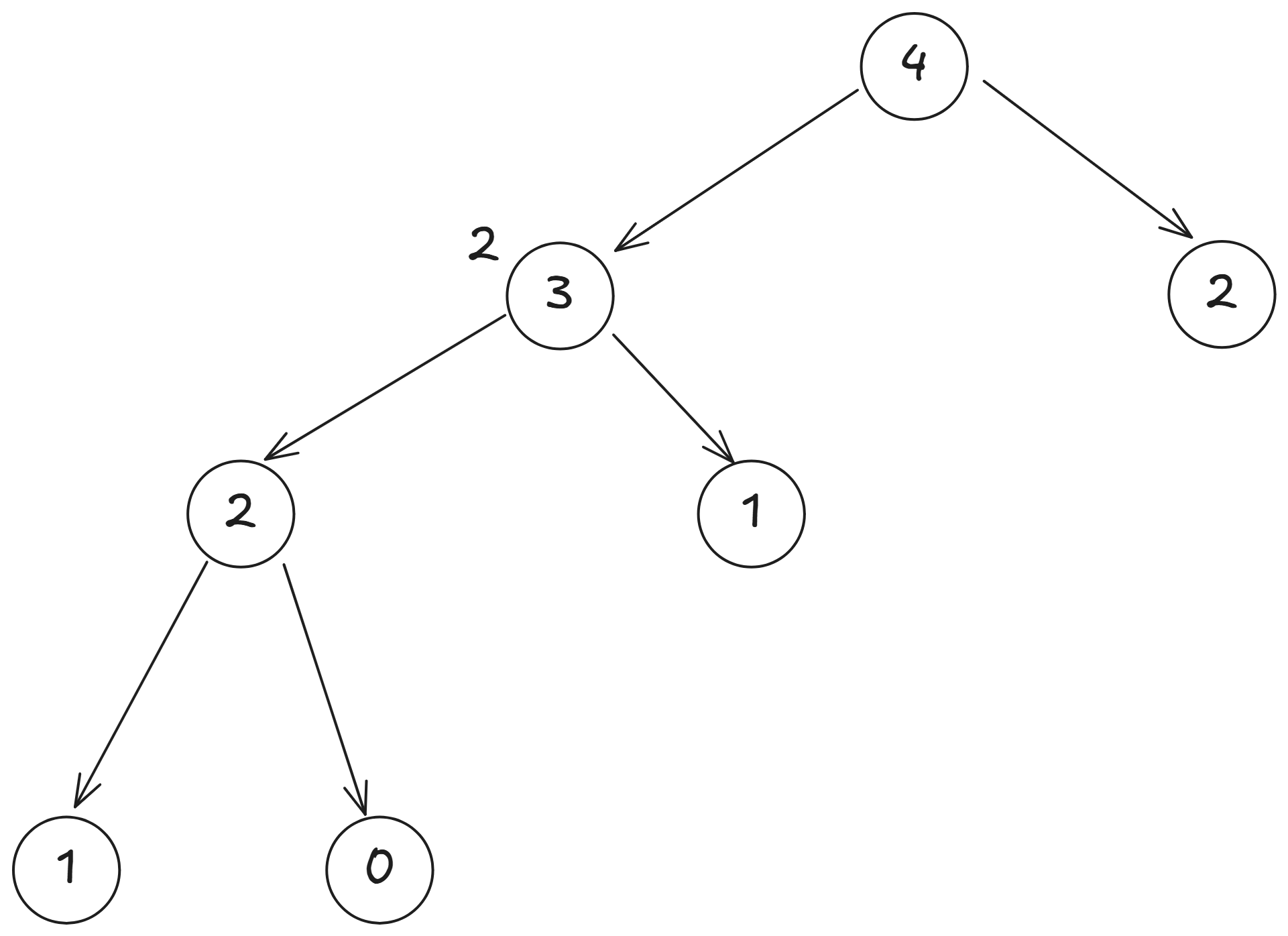
跟剛才算的過程一樣,算出 ,
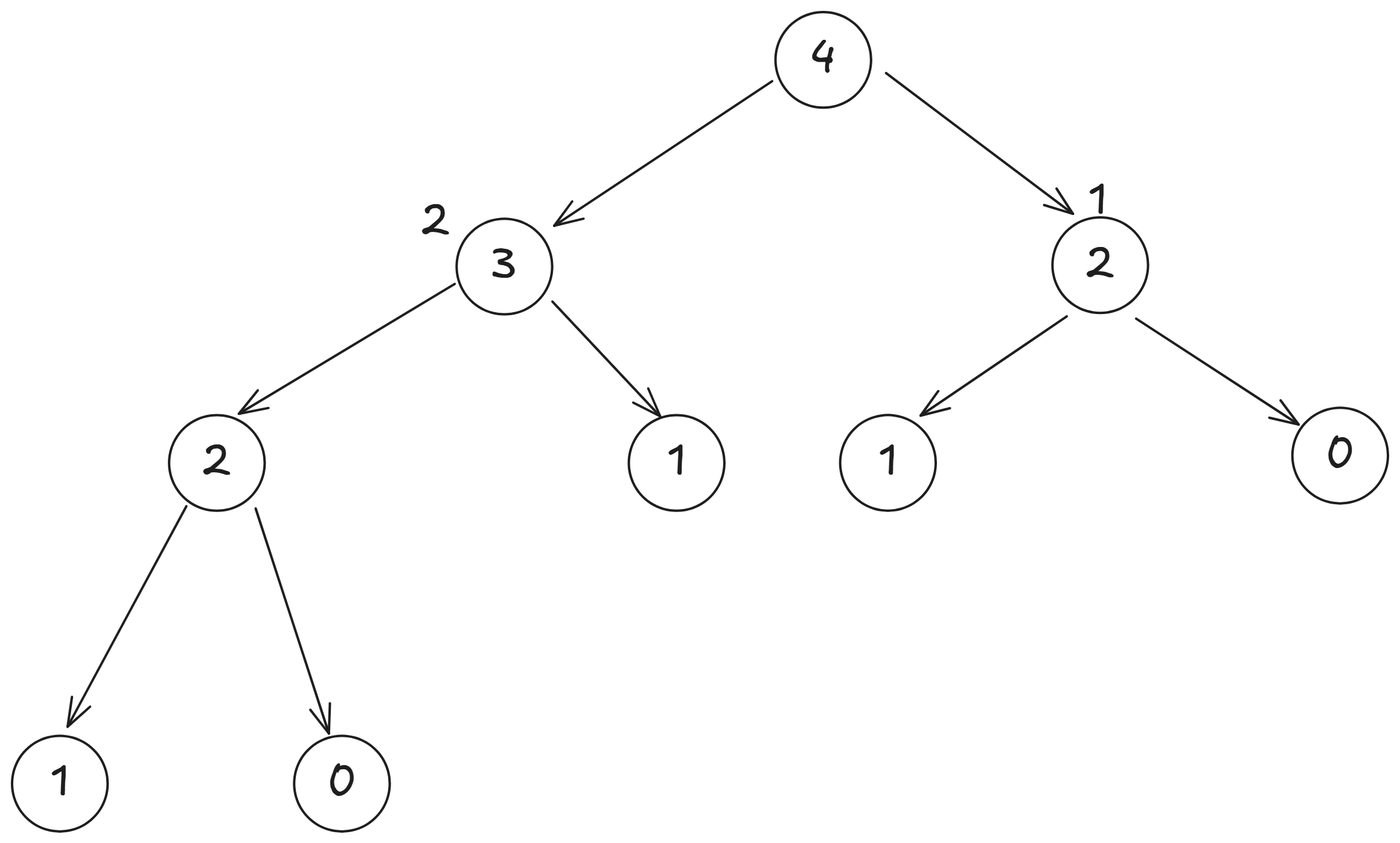
然後回到 , 因為 和 , 所以我們可以算出 。
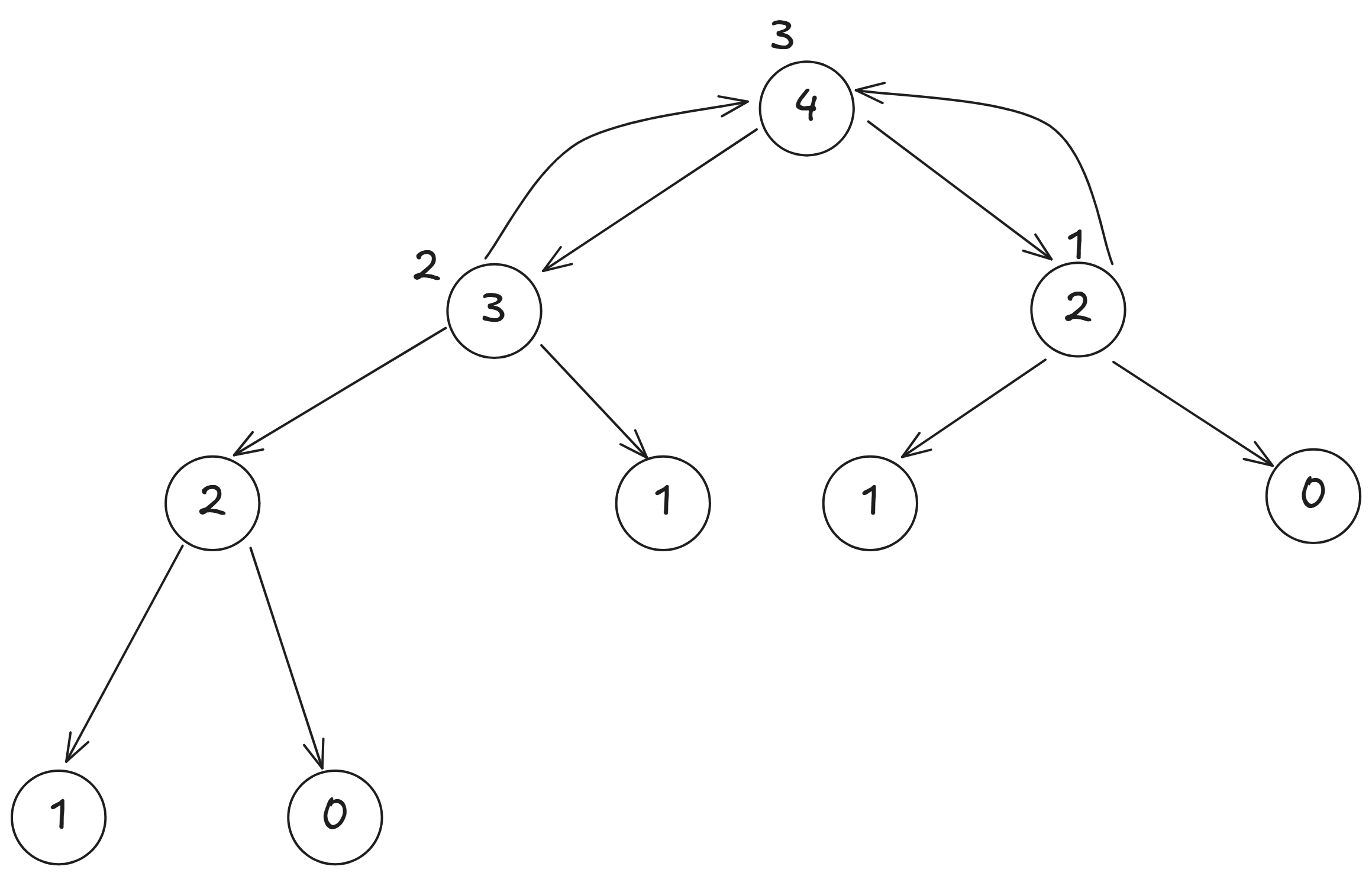
這樣的過程就是遞迴的過程, 每次呼叫函式時,都在解決一個更小的問題, 直到達到基本情況(base case), 然後再逐步回到原來的問題。
在實作遞迴時,我們需要注意兩個重要的部分:
- 基本情況(Base Case):這是遞迴的終止條件,當達到這個條件時,函式不再呼叫自己,而是直接返回一個值。
- 遞迴呼叫(Recursive Call):這是函式在其定義中呼叫自己,並且使用更小的問題來解決原始問題。
在實作遞迴時,我們需要確保每次呼叫函式時,問題的規模都在縮小, 並且最終能夠達到基本情況,這樣才能避免無限遞迴導致程式崩潰。
遞迴的實作
在 C++ 中,我們可以使用函式來實作遞迴, 函式的定義方式跟一般的函式一樣, 但是在函式內部,我們需要使用遞迴呼叫來解決問題。
#include <iostream>
using namespace std;
int fibonacci(int n)
{
if(n == 0)
return 0;
if(n == 1)
return 1;
return fibonacci(n - 1) + fibonacci(n - 2); // 遞迴呼叫
}
int main()
{
int n;
cin >> n;
cout << "Fibonacci(" << n << ") = " << fibonacci(n) << '\n';
return 0;
}
在這個範例中,我們定義了一個名為 fibonacci 的函式,
它接受一個整數參數 n,並返回費式數列的第 n 項。
在 fibonacci 函式中,我們使用了兩個 base case 來處理遞迴的終止條件:
- 當
n等於 0 時,返回 0。 - 當
n等於 1 時,返回 1。 如果n大於 1,我們就使用遞迴呼叫fibonacci(n - 1)和fibonacci(n - 2), 並將它們的結果相加,返回費式數列的第n項。
這樣的寫法可以讓我們很簡潔地實現費式數列的計算,
但是因為沒有使用任何額外的資料結構來儲存已經計算過的值,
所以這個遞迴的實現方式在計算較大的 n 時會非常慢,
因為會重複計算很多次相同的值。
因為上面的 fibonacci 函式是純函式,所以我們甚至可以先算 fibonacci(n - 2),
這樣對於結果是沒有影響的,也是純函式讓人放心的地方。
解答
解答
#include <iostream>
using namespace std;
long long factorial(int n)
{
if(n == 0)
return 1; // 基本情況
return n * 1ll * factorial(n - 1);
// 因為階乘的值可能會很大,但 int 乘 factorial(n - 1) 可能會溢位,
// 所以使用 1ll 來確保計算結果是 long long 型態
}
int main()
{
int n;
cin >> n;
cout << factorial(n) << '\n'; // 輸出階乘的值
return 0;
}
遞迴的優化
在遞迴的實作中,特別是像費式數列這樣的問題, 我們會發現有很多重複計算的部分, 這會導致效率非常低下。
我們其實可以使用陣列將已經計算過的值儲存起來, 這樣在需要計算相同的值時,就可以直接從陣列中取出,而不需要再次計算, 這種技術稱為記憶化遞迴(Memoization)。
#include <iostream>
using namespace std;
const int MAX_N = 1000; // 假設 n 的最大值為 1000
int memo[MAX_N]; // 儲存已計算過的值
int fibonacci(int n)
{
if(n == 0)
return 0;
if(n == 1)
return 1;
if(memo[n] != -1) // 如果已經計算過,直接返回
return memo[n];
memo[n] = fibonacci(n - 1) + fibonacci(n - 2); // 計算並儲存結果
return memo[n];
}
int main()
{
int n;
cin >> n;
memset(memo, -1, sizeof(memo)); // 初始化 memo 陣列
cout << "Fibonacci(" << n << ") = " << fibonacci(n) << '\n';
return 0;
}
在這個範例中,我們使用了一個名為 memo 的陣列來儲存已經計算過的費式數列的值。
在 fibonacci 函式中,我們首先檢查 memo[n] 是否已經被計算過,
如果已經計算過,就直接返回 memo[n] 的值。
這裡用到一個東西叫做 memset,
它是 C/C++ 中的一個函式,用來初始化一個陣列或記憶體區域。
在這個例子中,我們使用 memset(memo, -1, sizeof(memo)); 來將 memo 陣列的所有元素初始化為 -1,
這樣我們可以用 -1 來表示這個位置還沒有被計算過。
但 memset 只能用來初始化為 0 或 -1,
如果我們需要初始化為其他值,可以使用迴圈來完成。
而這個用陣列來儲存已經計算過的值的方式, 可以大幅提高遞迴的效率,被稱為 記憶化搜索(Memoization)或動態規劃(Dynamic Programming),我們在日後會詳細介紹動態規劃的概念。
輾轉相除法
不知道大家知不知道最大公因數這個東西,最大公因數指的是,對於兩個非負整數 和 , 最大公因數是能夠同時整除 和 的最大正整數, 我們用符號 來表示最大公因數。 在數學上,最大公因數有很多應用,例如在簡化分數、求最小公倍數等方面。
最直覺的做法就是,從 和 中取較小的數,然後從該數字開始,往下檢查每個數字是否能夠同時整除 和 , 直到找到第一個能夠同時整除的數字為止。 這種方法雖然簡單,但效率很低,特別是當 和 很大時。
這時候可能有些人高中數學會學到輾轉相除法(Euclidean Algorithm),這是一種更有效的計算最大公因數的方法。
輾轉相除法的基本思想是: 如果 和 的最大公因數是 ,那麼 也會是 和 的最大公因數, 指的是取餘數的運算,,因為 。
假設我們要求 ,
和 的公因數有 ,
和 的公因數有 ,
和 的公因數有 ,
和 的公因數有 ,
這樣我們就可以得到 。
的因數集都是相同的,自然最大公因數也是相同的, 證明如下:
,設 且 ,則 ,其中 都是正整數。
假設 是 和 的公因數, 代表 同時整除 和 ,計為 和 。
而 , 所以 也會整除 ,即 。 因此, 也是 和 的公因數, 即 和 , 所以 也是 的公因數, 因此 ,因為任何公因數 都會同時整除 和 , 當然最大公因數也是相同的。
輾轉相除法的實作
這裡就留給大家自己練習,在 C++ 17 之後,C++ 有內建的函數 std::gcd 可以直接使用。
河內塔
河內塔(Tower of Hanoi)是一個經典的遞迴問題, 最經典的定義是: 有三根柱子,A、B、C, A 柱子上有 n 個大小不一的圓盤,從小到大依次疊在一起, 目標是將這些圓盤從 A 柱子移動到 C 柱子, 在移動過程中需要遵守以下規則:
- 每次只能移動一個圓盤。
- 不能將大圓盤放在小圓盤上面。
- 只能使用 A、B、C 三根柱子。
大家可以先看一下這部影片來更深入理解河內塔具體的玩法。
當只有一個盤子的時候,我們只需要將它從 A 柱子移動到 C 柱子即可。 當有兩個盤子的時候,我們可以先將上面的盤子從 A 柱子移動到 B 柱子, 然後將下面的盤子從 A 柱子移動到 C 柱子,最後再將 B 柱子的盤子移動到 C 柱子。
當有三個盤子的時候,我們可以先將上面的第一個盤子從 A 柱子移動到 C 柱子, 然後將第二個盤子從 A 柱子移動到 B 柱子, 接著將第一個盤子從 C 柱子移動到 B 柱子, 然後將第三個盤子從 A 柱子移動到 C 柱子, 接著將第二個盤子從 B 柱子移動到 A 柱子, 再將第二個盤子從 B 柱子移動到 C 柱子, 最後將第一個盤子從 A 柱子移動到 C 柱子。 這樣就完成了河內塔的移動。
如果你想要搬動最下面的盤子,就需要先將上面的盤子全部搬到其他柱子上, 然後再將最下面的盤子搬到目標柱子上,接著才是將倒數第二個盤子搬到目標柱子上, 在那之前就又需要將上面的盤子搬到其他柱子上,
假設現在要將 個盤子從 A 柱子移動到 C 柱子, 我們可以將這個問題分解為三個步驟:
- 將上面的 個盤子從 A 柱子移動到 B 柱子。
- 將最下面的盤子從 A 柱子移動到 C 柱子。
- 將 B 柱子上的 個盤子從 B 柱子移動到 C 柱子。
而第三個步驟又可以被分解為三個步驟:
- 將上面的 個盤子從 B 柱子移動到 A 柱子。
- 將最下面的盤子從 B 柱子移動到 C 柱子。
- 將 A 柱子上的 個盤子從 A 柱子移動到 C 柱子。
這樣我們就可以看到,河內塔的問題可以被分解為更小的問題, 每次都將問題的規模縮小,直到達到只有一個盤子的情況。
為什麼這樣搬可以保證不會違反規則呢? 我們可以使用高中學過的數學歸納法來證明。
目標是證明對於任意的正整數 ,
我們可以合法地將 個盤子從當前的柱子移動到目標柱子。
Base Case:
當 時,只有一個盤子,我們可以直接將它從當前的柱子 (A) 移動到目標柱子 (C)。
Inductive Hypothesis:
假設對於 的情況,我們可以合法地將 個盤子從當前柱子移動到目標柱子。
Inductive Step:
現在我們要證明對於 的情況,我們也可以合法地將 個盤子從當前柱子 (A) 柱子移動到目標柱子 (C)。
我們可以將 個盤子分為兩部分:
- 最下面的盤子(第 個盤子)。
- 上面的 個盤子。
根據歸納假設,我們可以合法地將上面的 個盤子從當前柱子 (A)移動到目標柱子 (B),
所以現在 A 柱子上只剩下最下面的盤子(第 個盤子),B 柱子上有 個盤子。
C 柱子上沒有盤子。
接著,我們可以將最下面的盤子(第 個盤子)從 A 柱子移動到 C 柱子,因為 C 柱子上沒有盤子,所以這個操作是合法的。
現在 A 柱子上沒有盤子,B 柱子上有 個盤子,C 柱子上有最下面的盤子(第 個盤子)。
最後,我們可以將 B 柱子上的 個盤子從 B 柱子移動到 C 柱子,
因為 C 柱子上只有最下面的盤子(第 個盤子),
再加上歸納假設的前提,我們可以合法地將這些盤子從 B 柱子移動到 C 柱子。
這樣我們就完成了對於 個盤子的合法移動。
所以我們可以得出結論,對於任意的正整數 , 我們都可以合法地將 個盤子從當前柱子移動到目標柱子, 這樣的遞迴過程可以一直進行下去,直到所有盤子都被合法地移動到目標柱子上。
而遞迴過程可以用以下的類似實作來達成:
void move_plate(int number_of_plates, char from, char to, char aux)
{
if(number_of_plates == 1)
{
cout << "Move plate from " << from << " to " << to << '\n'; // 基本情況,直接移動盤子
return;
}
move_plate(number_of_plates - 1, from, aux, to); // 將上面的盤子從 from 移動到 aux
move_plate(1, from, to, aux); // 將最下面的盤子從 from 移動到 to
move_plate(number_of_plates - 1, aux, to, from); // 將 aux 上的盤子從 aux 移動到 to
}
在這個函式中,我們使用了四個參數:
number_of_plates:表示目前要移動的盤子數量。from:表示要從哪個柱子移動盤子。to:表示要將盤子移動到哪個柱子。aux:表示輔助柱子,用來暫時存放盤子。
在基本情況下(只有一個盤子),我們可以直接將盤子從 from 柱子移動到 to 柱子,
而在遞迴呼叫中,我們將問題分解為更小的問題,
每次都將盤子數量減少 1,直到達到可以直接解決的情況。
根據計算,搬動 個盤子需要的最小步數為 , 這是因為每次搬動盤子都需要將上面的盤子先移到其他柱子上, 然後再將最下面的盤子移到目標柱子上, 然後再將上面的盤子從其他柱子移到目標柱子上, 這樣的過程需要重複進行 次, 所以總步數為 。
很多教學都只會講到這一步,但這個遞迴函數其實是一個非常糟糕的函數, 也許有同學看到這裡還是一知半解,原因是什麼?
首先,這個函數沒辦法直接得知每個盤子是怎麼移動的,以及每個柱子上有多少個盤子, 這樣的函數只能告訴你最終的結果,而且其實你偷偷移動下面三個函數的順序,會發現答案就錯了, 並不符合純函數的定義。
所以我想以純函數的角度時做一個直觀的河內塔, 也許它所需要花費更多記憶體空間,但它能夠清楚地告訴你每個盤子是怎麼移動的。
我們想要知道盤子具體是怎麼被移動的,所以需要用三個 vector<int> 來代表三根柱子上的盤子編號,
河內塔函數需要回傳一個 vector<vector<vector<int>>,
這個三維陣列的第一維代表每個盤子移動的步驟,清楚記錄每一個移動後盤子擺放的狀態,
所以我們函數會有四個輸入參數:
init_state:初始狀態,vector<vector>,三個 vector 分別代表 A、B、C 三根柱子上的盤子編號。 number_of_plates:目前要移動的盤子數量。from:要從哪個柱子移動盤子。to:要將盤子移動到哪個柱子。
先寫一個輔助函式 move_plate,用來實際移動盤子,並產生下一個狀態。
vector<vector<int>> move_plate(const vector<vector<int>>& state, int number_of_plates, int from, int to)
{
vector<vector<int>> next_state = state; // 複製當前狀態
assert(next_state[from].size() >= number_of_plates); // 確保從柱子上有足夠的盤子可以移動
vector<int> temp; // 用來暫存從柱子上移動的盤子
for(int i = 0; i < number_of_plates; ++i)
{
temp.push_back(next_state[from].back()); // 將從柱子上最上面的盤子移動到暫存區
next_state[from].pop_back(); // 從原柱子上移除最上面的盤子
}
for(int i = 0; i < number_of_plates; ++i)
{
next_state[to].push_back(temp.back()); // 將暫存區的盤子移動到目標柱子上
temp.pop_back(); // 從暫存區移除已經移動的盤子
}
return next_state; // 返回新的狀態
}
需要使用暫存區來暫存從柱子上移動的盤子,因為順序不能錯, 假設現在的狀態是
{
{3, 2, 1}, // A 柱子上的盤子
{}, // B 柱子上的盤子
{} // C 柱子上的盤子
}
如果要將上面的兩個盤子從 A 移動到 C,
結果應該要是
{
{3}, // A 柱子上的盤子
{}, // B 柱子上的盤子
{2, 1} // C 柱子上的盤子
}
所以需要暫存區來確保盤子的順序不會錯亂。
有了這個輔助函式之後,我們就可以實作河內塔的主函式了。
vector<vector<vector<int>>> hanoi(const vector<vector<int>>& init_state, int number_of_plates, int from, int to)
{
if(number_of_plates == 1)
return {move_plate(init_state, 1, from, to)}; // 基本情況,直接移動盤子
int aux = 3 - from - to;
// (0 + 1 + 2) = 3,所以 3 - from - to 就是剩下那根柱子的編號
// 協助函式 move_plate 會返回下一個狀態
vector<vector<int>> s1 = move_plate(init_state, number_of_plates - 1, from, aux); // 將上面的盤子從 from 移動到 aux
vector<vector<int>> s2 = move_plate(s1, 1, from, to); // 將最下面的盤子從 from 移動到 to
vector<vector<int>> s3 = move_plate(s2, number_of_plates - 1, aux, to); // 將 aux 上的盤子從 aux 移動到 to
vector<vector<vector<int>>> result;
auto &&step1 = hanoi(init_state, number_of_plates - 1, from, aux);
auto &&step2 = hanoi(s1, 1, from, to);
auto &&step3 = hanoi(s2, number_of_plates - 1, aux, to);
// 驗證每個步驟的狀態是否正確
assert(step1.back() == s1);
assert(step2.back() == s2);
assert(step3.back() == s3);
result.insert(result.end(), step1.begin(), step1.end());
result.insert(result.end(), step2.begin(), step2.end());
result.insert(result.end(), step3.begin(), step3.end());
return result; // 返回所有步驟的狀態
}
只有在 number_of_plates == 1 的時候,才會直接返回移動盤子的結果,也就是真正的移動盤子,
其他情況下,會先計算出下一個狀態,然後再遞迴呼叫 hanoi 函式,
將問題切分成三個部分,
每次都將盤子數量減少 1,直到達到 Base Case。
這樣的實作方式可以清楚地記錄每個盤子是怎麼移動的,
每次呼叫 hanoi 函式都會返回一個包含所有步驟狀態的三維陣列,
每個步驟的狀態都是一個二維陣列,代表三根柱子上的盤子編號。
以 盤子數量為 3 的河內塔為例, 來看看結果:
{3 2 1}
{}
{}
{3 2}
{}
{1}
{3}
{2}
{1}
{3}
{2 1}
{}
{}
{2 1}
{3}
{1}
{2}
{3}
{1}
{}
{3 2}
{}
{}
{3 2 1}